The cloud is not only about greenfield projects. Over the last few years I have accompanied several enterprises in large migration projects from on-premises to the Amazon Web Services (AWS). This blog post gives an overview of typical obstacles for lift & shift architectures and points out possible solutions.
Increase reliability of a single EC2 instance
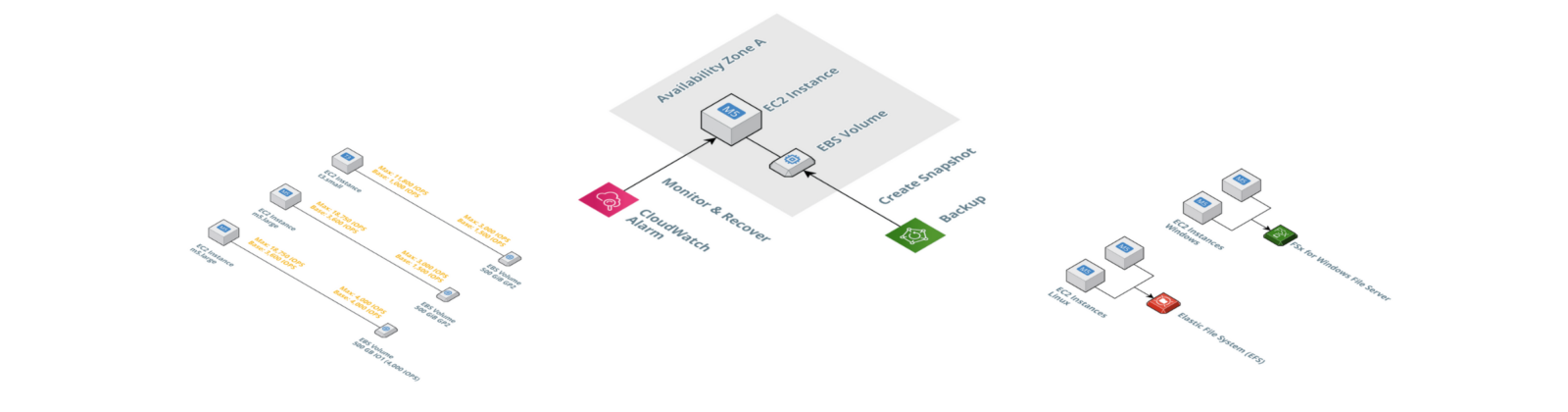
Whenever possible, you should avoid running parts of your workload on a single EC2 instance. Instead, deploy your application to least two EC2 instances in two Availability Zones. Unfortunately, there are a lot of legacy applications that do not support running on two different machines in parallel. In that case, a single EC2 instance is your only option. But how do you make the best of this situation?
- Set up a CloudWatch alarm to automatically recover the single EC2 instance. Doing so will replace a failed machine within the same AZ automatically.
- Configure AWS Backup to create snapshots of the attached EBS volume regularly (e.g., every 12 hours).
I’ve created all the architecture diagrams for this blog post with Cloudcraft. Enjoy!

Using a shared file system that replicates data among multiple AZs is another option. In that case, using an Auto Scaling Group with minimum and maximum size of 1 allows you to recover from an instance and availability zone failure.
Be aware of burstable performance
I’ve been tasked to debug performance issues after a lift & shift migration many times. Commonly, the performance decreased significantly a few hours after migrating the workload from on-premises to the cloud. The reason: a lot of resources come with burstable performance. After a while, the resources fall back to their baseline performance, which slows down your workload significantly.
When designing an architecture for a high-load scenario, make sure you are picking resources without burstable performance.
| Service | Aspect | Burstable Options | Constant Options |
| EC2 | CPU | The instance types t2, t3, t3a come with burstable CPU performance. | All other instance types offer constant CPU performance (e.g., m5). |
| EC2 | Network | Most instance types come with burstable network performance. | Some instance types offer constant network performance (e.g., m5.8xlarge). |
| EC2 | Storage I/O(EBS) | Many instance types come with burstable storage I/O throughput. | Some instance types offer constant EBS throughput (e.g., m5.4xlarge). |
| EBS | Storage I/O | An EBS volume with type gp2, st1, or sc1 comes with burstable I/O performance. | An EBS volume of type io1 guarantees a constant I/O performance. |
The same applies to services that are using EC2 instances under the hood. RDS, for example.
Optimize I/O throughput between EC2 and EBS
Elastic Block Store (EBS) provides network-attached block storage for EC2. Important to note, there is a network connection between your virtual machine (ECS instance) and your volume (EBS volume). The maximum I/O throughput depends on two factors: the instance type of your EC2 instance and the type and configuration of your EBS volume.
For example, an EC instance of type t3.small comes with a baseline performance of 1,000 IOPS (IO operations per second). Where as, a general purpose (gp2) EBS volume with 500 GiB comes with a baseline performance of 1,500 IOPS. Therefore, the EC2 instance cannot saturate the maximum I/O throughput to the volume long-term.

A mismatch between the instance type and the volume type and configuration leads to overspending or insufficient performance. Therefore, you should bookmark the following pages of the AWS documentation to do the math when picking an instance and volume type.
Please note that the same applies to RDS. At least, as long as you are not using Aurora.
Limitations of shared file systems
Adding a shared file system to your architecture allows multiple EC2 instances to access the same files concurrently. Also, a shared file system on AWS automatically replicates the data among multiple availability zones.
Two services offer shared file systems:
- Elastic File System (EFS), a simple, scalable, fully managed elastic NFS file system.
- Amazon FSx for Windows File Server, a fully managed file storage built on Windows Server.

EFS distributes data among multiple availability zones by default and scales storage capacity on-demand. You have to pay for the consumed storage capacity and for the optionally provisioned throughput. EFS uses the NFSv4 protocol and is compatible with ECS instances running Linux only.
Amazon FSx for Windows File Server is a heavy weight solution, compared to EFS. For example, FSx requires a Microsoft Active Directory managed by you or AWS. However, as FSx is using the Service Message Block (SMB) protocol mounting the shared file system works on Windows, Linux and even MacOS. FSx is billed per consumed storage as well as throughput capacity.
Fine granular control with Security Groups
Back in the on-premises network firewall rules referenced IP address ranges. Typically, the network was thoughtfully divided into subnets and static IP addresses had been assigned to machines. The cloud is a more dynamic place. Therefore, I do not recommend using static private IP addresses within firewall rules any more.
Use security groups to control incoming and outgoing traffic to machines instead. Think of a security group as a host-level firewall for load balancers, EC2 instances, and RDS database instances.
A security group comes with a superpower: a security group can reference another security group within a rule instead of specifying an IP address range. Let’s have a look at a simple example:
- The Security Group “Load Balancer” allows incoming traffic on port 443 TCP from the Internet (0.0.0.0/0).
- The Security Group “Application” allows incoming traffic on port 443 TCP from the Security Group “Load Balancer”.
- The Security Group “Database” allows incoming traffic on port 5432 TCP from the Security Group “Application”.

Keep your network architecture as simple as possible and use security groups to control traffic on a fine granular level, that hasn’t been seen on-premises before.
Multicast is not supported by default
Some legacy workloads, especially distributed application systems, rely on multicast. By default, AWS does not support multicast within your VPC (Virtual Private Cloud). How to migrate a legacy application that requires multicast?
- Try to get rid of the multicast requirement. Oftentimes, there is an alternative to relying on multicast.
- Use AWS Transit Gateway to enable multicast within your VPCs. Please note, that the feature is currently only available in the US East (N. Virginia) region and introduces some limitations to your architecture as well (see Multicast on transit gateways).
Load Balancing with Sticky Sessions
AWS offers fully-managed load balancers: Elastic Load Balancing (ELB). By default, a load balancer routes each incoming request to one of the registered EC2 instances. Therefore, sequential requests from the same client will not end up on the same machine.

However, many legacy applications do not follow the concept of a stateless server. Instead legacy applications store state in memory, or even worse on disk. Therefore, you need to make sure that all requests from one client get served by the same EC2 instance.
To do so, you need to enable sticky sessions. After doing so, the ELB will forward all requests from the same client to the same EC2 instance. The session sticks to a certain EC2 instance.

However, not all types of AWS’s load balancers do support sticky sessions. Also the available mechanisms for sticky sessions are very limited compared to what is typical on an on-premises load balancer.
| Load Balancer Type | Sticky Sessions? | Mechanism | Details |
| Application Load Balancer (ALB) | ✅ | Cookie | The Load Balancer creates stickiness cookies named AWSALB. The duration is set with each request. Therefore, if the client sends a request before each duration period expires, the sticky session continues. |
| Network Load Balancer (NLB) | ❌ | n/a | |
| Classic Load Balancer (CLB) | ✅ | Cookie | Only HTTP/HTTPS listeners support sticky sessions.Reuse existing session cookies or let CLB add its own cookies. |
Load Balancer with Static IP Addresses
Do clients connect to your load balancer by using a static IP address? Or does a 3rd party rely on a static IP address to create a firewall rule to allow traffic from your load balancer? The Classic Load Balancer (CLB) and Application Load Balancer (ALB) do use a dynamic number of IP addresses. Therefore, a client uses a DNS name that resolves to those dynamic IP addresses when connecting to a CLB/ALB.
There are two common options to implement static public IP addresses for your load balancer:
- Use a Network Load Balancer (NLB) which comes with a static IP address per availability zone.
- Use Global Accelerator to get two static IP addresses and forward the traffic to your ALB or EC2 instances.
RDS is a must have but comes with limitations
Are you migrating a workload that involves a relational database: PostgreSQL, MySQL, MariaDB, Oracle Database, or SQL Server? Use the Relational Database Service (RDS) instead of operating one of these database systems on top of EC2 yourself. RDS provides a high available database replicated among at least two availability zones out-of-the-box. On top of that, patching, resizing, and backing up the database system are solved problems as well. That’s a game changer and one of the biggest advantages you can get out of a lift & shift migration.
To be able to provide a relational database as a service, AWS introduced some restrictions.
- You cannot log into the machine via SSH or RDP.
- You might not be granted database administrator (DBA) access to 100%.
- You cannot access the file system directly.
- Some features are not supported (e.g., RDS Oracle does not support Database Vault, Flashback Database, and Real Application Testing)
Verify that RDS failover will work
When using RDS for a production-workload you should enable the “Multi-AZ” feature. RDS will spin up two machines in two different availability zones. One machine becomes the primary instance and answers all read and write requests. The other instance becomes the standby instance. RDS replicates data between the primary and the secondary instance synchronously.
A DNS name like mydb.xyz.us-east-1.amazonaws.com points to the IP address of the primary instance. In case of a failure, or during maintenance, the standby instance becomes the new primary instance. Therefore, RDS updates the DNS name.

Make sure your application is capable of re-connecting and re-resolving the database’s DNS name. Not all applications, runtimes, libraries do so by default. Some are even not capable of doing so. Before going live, make sure you have triggered a failover to the standby instance and double check whether your application is capable of connecting to the database afterwards.
Summary
All the best with migrating your workloads to the cloud. Watch out for the following obstacles and your lift & shift project will become a huge success.
- Increase reliability of a single EC2 instance: configure an auto recovery alarm and snapshots.
- Be aware of burstable performance: CPU, storage, and network.
- Optimize I/O throughput between EC2 and EBS: make sure your instance type provides sufficient I/O throughput.
- Limitations of shared file systems: EFS accessible from Linux systems only, FSx requires Active Directory.
- Fine granular control with Security Groups: reference security groups of up-/downstream components to avoid having to think about IP address ranges.
- Multicast is not supported by default: try to modify your application to get rid of the multicast requirement or use Transit Gateway to enable multicast.
- Load Balancing with Sticky Sessions: only Cookie based sticky sessions are supported by CLB and ALB.
- Load Balancer with Static IP Addresses: use a NLB or Global Accelerator and ALB to get static IP addresses for your load balancer.
- RDS is a must have but comes with limitations: no way to SSH/RDP into your database server, no direct access to the file system. But: RDS makes the difference for lift & shift projects.
- Verify that RDS failover will work: applications need to be able to re-connect to the database as well as to re-resolve the database’s DNS name.