
A document-oriented database stores keys mapped to JSON documents. You can query all documents in such a document-oriented database and retrieve only parts of documents to save network bandwidth.
A data model for a document-oriented database looks different from a relation model where you usually have many tables that reference each other. In an online shop, you could easily have tens of tables, like users, settings, sessions, favorites, and carts, while you might store all of that in a single user document. All 1:1, 1:n relationships, can be stored in one document. If you have many m:1, or m:n relationships you likely run into issues with document-oriented databases.
Many NoSQL databases (all that I highlight in the article) allow you to scale workloads horizontally by adding more nodes. Horizontal scaling is usually cheaper than scaling vertically, where hardware gets costly at the end of the spectrum. It is still difficult to compare the scalability options because some NoSQL databases only allow to scale reads horizontally or have some upper limits on the number of nodes that can be added.
Keep in mind that most NoSQL databases use the concept of eventual consistency to support the system’s scalability. If you need read-after-write consistency, you have to look for stronger guarantees. Some NoSQL systems provide options to read with strong or eventual consistency to allow your application to optimize database access.
After comparing all database options on AWS, I will discuss the document-oriented database offerings on AWS in this article.
DynamoDB
Amazon DynamoDB is a database with virtually unlimited scaling. Both in terms of storage and queries per second. Documents (aka items) can have a size of up to 400 KB and are stored in a table that can be of infinite size1. You pay for the used storage and read and write activity either on-demand or by provisioned capacity.
The core assumptions of DynamoDB are:
- Items are accessed in an evenly distributed manner: Avoid “hot” items that are accessed significantly more often than other items.
- Items are independent: Only one write operation can run on for a single item at a time. Use transactions if you need to change multiple items in an atomic operation.
The following best practices should be followed:
- Items cannot be sorted in a table (there is no ORDER BY) unless you provide a sort key and/or a local secondary index.
- When reading items, you have to select the index that you use. There is no query optimizer that ensures that your query is executed most efficiently! The query is executed exactly in the way you define it.
- Avoid scanning a table to retrieve items. Look up items based on their key. You can create global secondary indexes if you need to lookup an item based on multiple attributes.
You can deploy DynamoDB into multiple AWS regions and keep the data in sync. This enables users all over the world to access their data with minimal latency. If a user boards a plane in Germany, she can still access her data in the US with minimum latency.

DocumentDB
Amazon DocumentDB provides a “mostly” MongoDB 3.6 API compatible database hosted by AWS.
A shortlist of missing features:
- Storage compression not available (when migrating from MongoDB to DocumentDB your storage usage likely grows)
- Geospatial operations not available
- Map-Reduce operation not available
- GridFS not available
According to MongoDB, DocumentDB is ~37% compatible with the latest MongoDB Atlas feature set. DocumentDB is powered by Aurora storage technology and can scale horizontally up to 15 read replicas to scale read workloads. Writes can only be scaled vertically. I created the following cloud diagram with Cloudcraft to visualize the architecture.
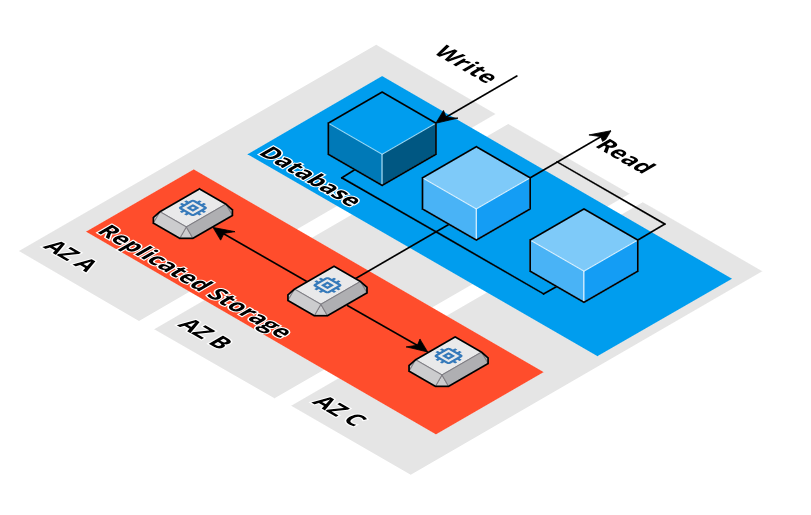
You pay for the number of database nodes that are running, used storage, and disk IO.
MongoDB Atlas
MongoDB Atlas is a service offered by MongoDB, not Amazon. The MongoDB cluster runs in an AWS account operated by MongoDB. As the following figure shows, you can get private network access to the cluster using VPC peering or AWS Private Link.
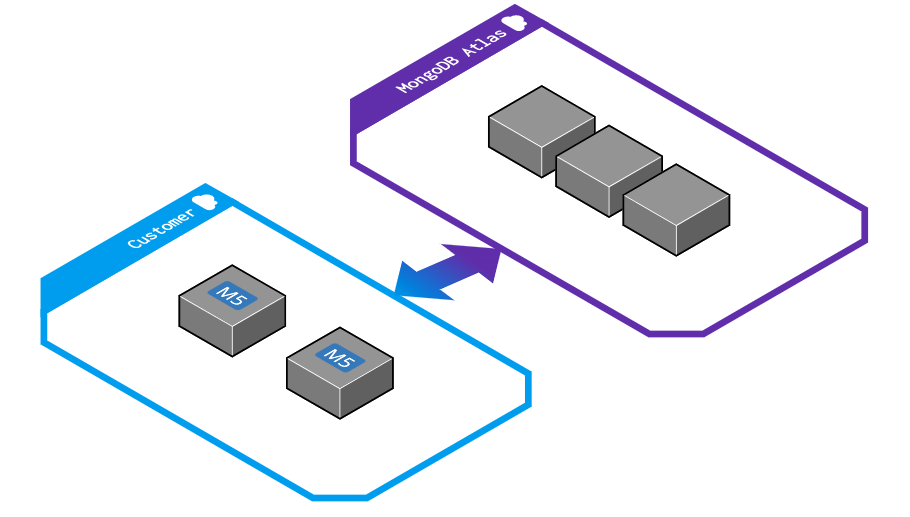
The biggest advantage is that it supports all features of MongoDB and the latest versions. MongoDB provides features that are closer to traditional databases. You can run a query without thinking about keys, indexes. The query optimizer will figure this out for you.
Summary
The following table provides a comparison of the different managed document-oriented database options on AWS.
| DynamoDB | DocumentDB | MongoDB Atlas | |
| Consistency | Consistent reads are possible | Consistent reads only from primary node (limits scalability) | Consistent reads are possible |
| Max. document size | 400 KB | 16 MB | 16 MB |
| Max. table size | unlimited1 | 32 TB | 32 TB |
| Max. Indexes / table | Global: 202 Local: 5 | 64 | 64 |
| Query optimizer | no | yes | yes |
| Pricing | on-demand or provisioned | database layer: provisioned storage layer: on-demand | provisioned |
| Smallest HA setup costs | $0.25 / GB / month+ reads / writes | $400 / month+ $0.10 / GB / month+ reads / writes | $115 / month+ storage if you need more than provided by default |
| Global replication | yes | no | yes |
| Transactions | yes | yes | yes |
| Scaling | horizontally | reads: horizontally (max. 15 nodes) writes: vertically (max. 1 node) | horizontally (max. 402 nodes) |
| Auto Scaling | yes | database layer: no storage layer: yes | yes |
| Backups | yes | yes | yes |
1All Items with the same partition key (but different sort key) must be <= 10GB (includes local secondary indexes as well). https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/LSI.html#LSI.ItemCollections
2Vendor might increase this limit.