AWS provides many building blocks. As architects, we have to choose the right building blocks to construct our systems. But sometimes, the proper building block is not available, and we have to make compromises. In this blog post, I show four unusual AWS architectures that deal with AWS’s limitations in creative ways.

Active-Standby
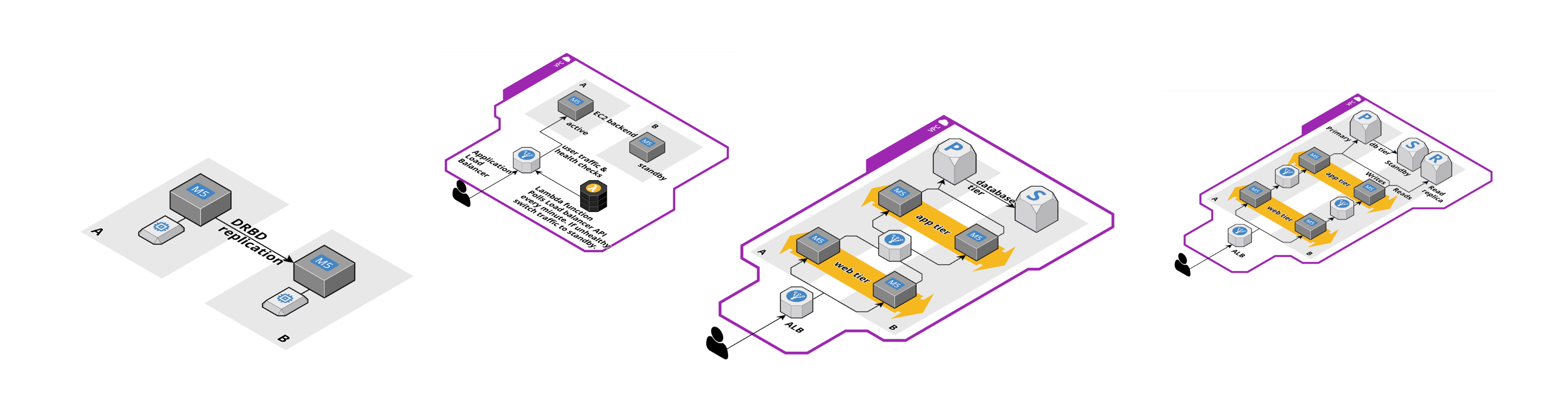
Not all applications support active-active deployments where multiple instances of an application server run simultaneously and serve traffic. Sometimes, only one application server is allowed to receive user traffic at a time. For example, if the application stores session state in memory. But you still want to prepare for failure. In this scenario, an active-standby deployment can help as the following figure — drawn with Cloudcraft — shows.

You launch and install two EC2 instances in two different Availability Zones (AZs). The Application Load Balancer (ALB) has only a single target, the active EC2 instance. The ALB will send a health check to the active instance at a regular interval. Ensure to enable cross AZ traffic support on your ALB. On top of that, a Lambda function is configured to poll the ALB API every minute. If the target status changes to unhealthy, the Lambda function deregisters the unhealthy target and registers the standby as a target. Within 90 seconds, user traffic can continue.
This architecture also allows you to perform blue-green deployments. You can install the new release on the standby instance. Once the installation is complete, switch the active with the standby instance on the load balancer. If the release causes issues, you can easily switch back. If the release works as expected, you can install it on the previously active instance.
Three-tier architecture with AZ preference
A typical three-tier-architecture consists of web servers, application servers, and database servers. The typical AWS architecture looks like this:

The EC2 instances of the web and app tier run in multiple AZs and are fronted by a load balancer (e.g., Application Load Balancer). The RDS database is deployed in Multi-AZ mode, but all reads/writes happen on the primary database instance. This architecture will cause a lot of cross AZ traffic. E.g., if an app server from AZ B sends a query to the database in AZ A.
You might ask yourself: What’s the problem with cross AT traffic? First, you pay $0.01 per GB of cross AZ traffic while traffic in the same AZ is free. Second, you will experience additional latency (~1ms). For some applications, we need to reduce cross AZ traffic to the minimum. The following figure shows the evolution of the previous architecture.

I want to highlight two changes. Once the traffic arrives at a web server, it stays in the same AZ and is forwarded to an application server in the same AZ. If possible, you could try to get rid of the load balancer between your web and app tier.
The second change applies to the database tier. To avoid cross AZ traffic for reads, we added a read replica. The application server has to send writes to another database endpoint than reads to make this work! The write traffic will still cross AZ boundaries.
EBS replication among two AZs
EBS volumes are bound to a single AZ. During an AZ outage, the data will not be available. The good news is that the data is not lost. As soon as the AZ recovers, you can re-access your data. But what if you need to access the data earlier? What if you need to guarantee to recover within a specific time?
One option is to create EBS snapshots. If you run snapshots every day, you can lose up to 24 hours of data. If you run snapshots every hour, you can lose up to 1 hour of data. Unfortunately, you can not reduce your Recovery Point Objective (RPO) significantly lower than 60 minutes with snapshots. Additionally, If you restore an EBS volume from a snapshot, the data is copied to the volume asynchronously on first access. Therefore, your EBS volume is initially very slow, which is likely not tolerable if your RTO is lower than the time it takes to restore the volume from the snapshot.
So what’s the solution to the problem? On Linux, we can use a DRBD (Distributed Replicated Block Device) to replicate all changes from one volume to another volume, as the following figure shows.

DRBD requires that you have two EC2 instances running. The instance in AZ A mounts the volume in AZ A. The instance in AZ B mounts the volume in AZ B. The DRBD software replicates all changes from one side to the other. This way, you always have a hot copy of your EBS volume. DRBD allows you to replicate synchronously (slows down performance but provides a minimal RPO) or asynchronously (better performance, but you risk losing a tiny slice of data in case of a failure).
PS: If you are lucky, you find a native data replication mechanism provided out of the box by the software application you try to run!
Oracle APEX on Fargate and RDS
Oracle Application Express (APEX) is a way to create CRUD applications without code that interact with an Oracle database. We see many enterprise applications that are based on APEX. We asked ourselves: What’s the most modern way to run this? It turns out that you can run an APEX application in a Docker container on Fargate.
This architecture minimized the operational effort to a minimum. It was never easier to run enterprise applications based on APEX in the cloud! No rewrite required.
Summary
AWS covers most use cases already. But sometimes, you discover that your requirements can not be satisfied. Now it’s time to be creative. Can you use an AWS service in an unusual way? Is there a feature that you can use slightly differently to achieve your goal? Can you combine AWS with software from 3rd parties (open source or commercial) to achieve our goal? So far, I always found a way to implement a solution. And of course, always challenge the requirements!